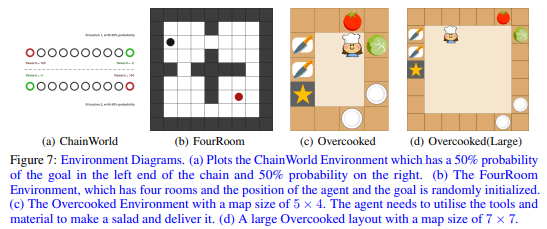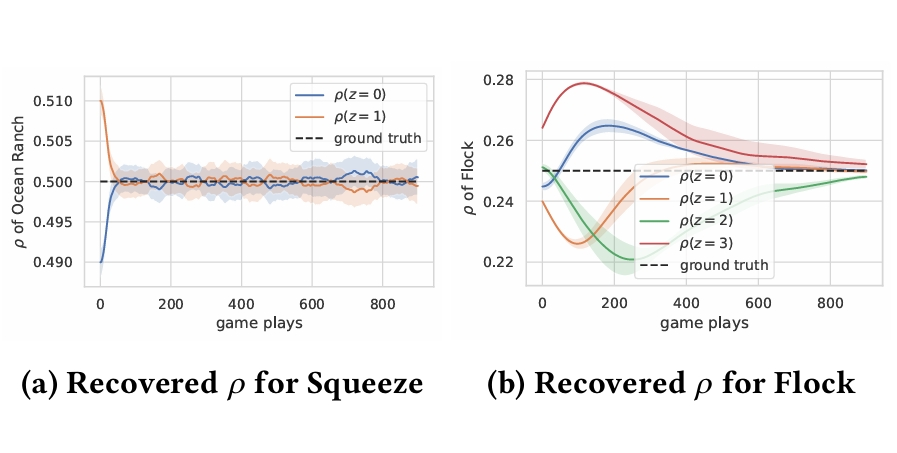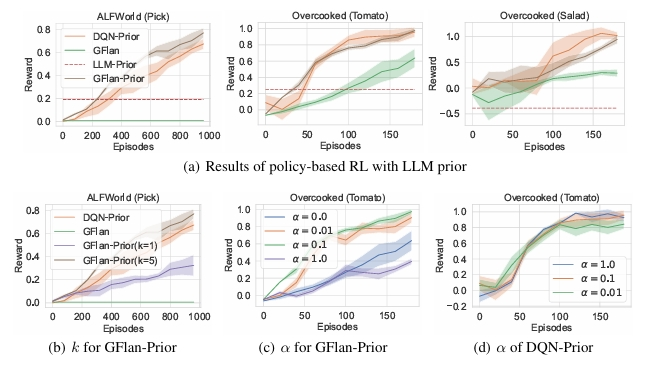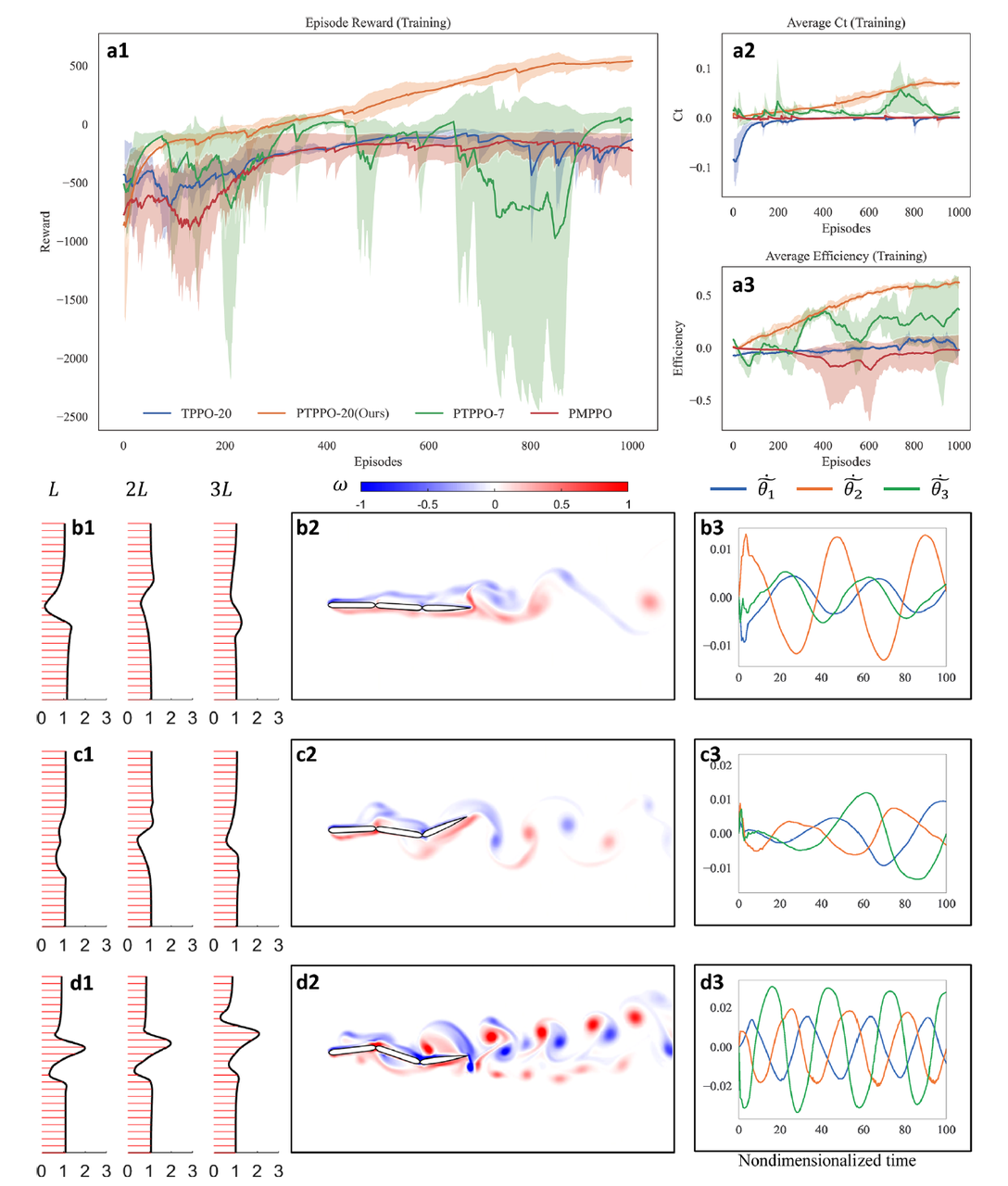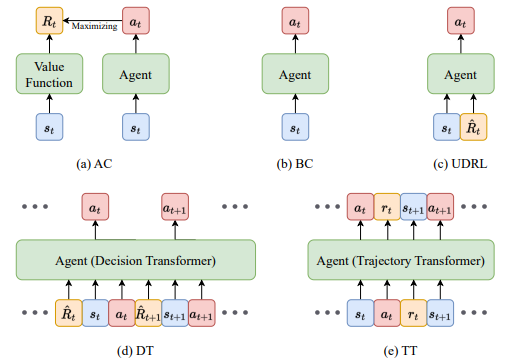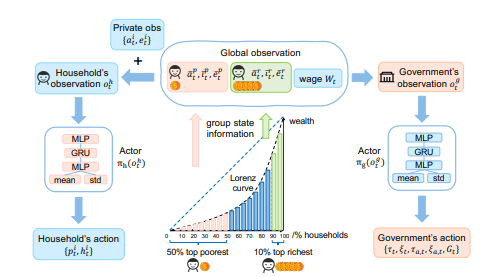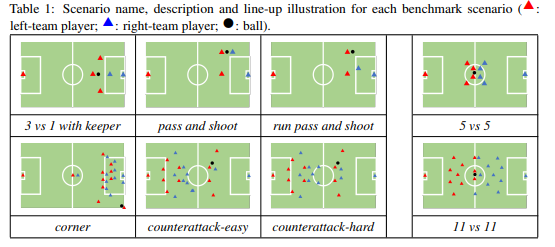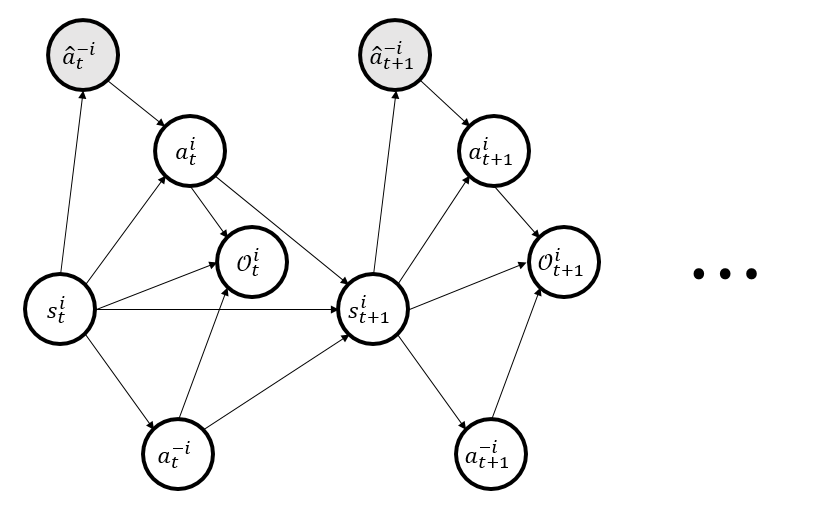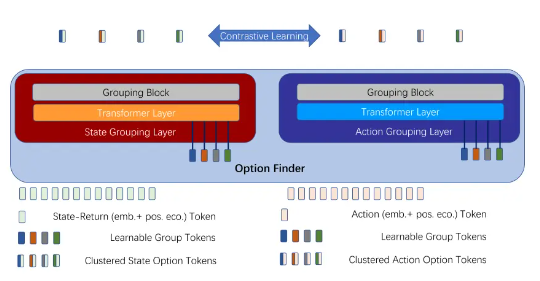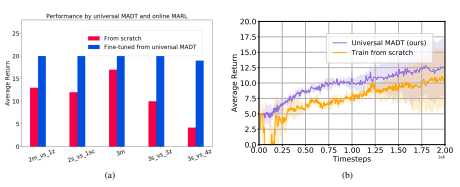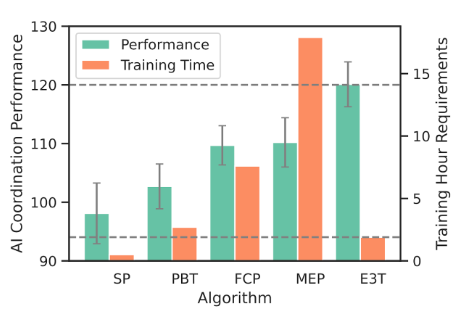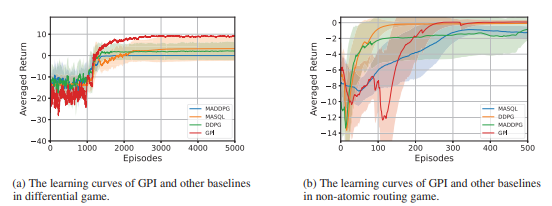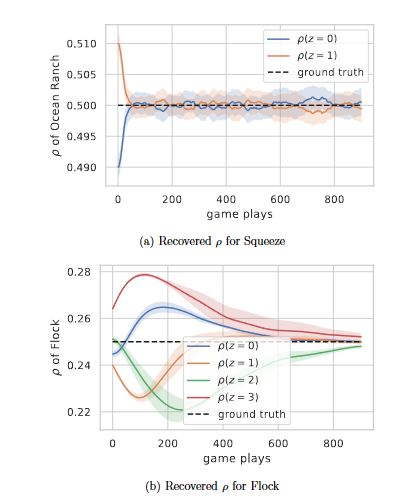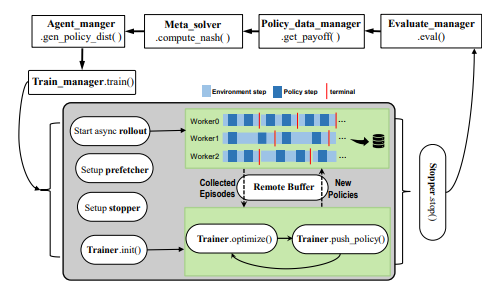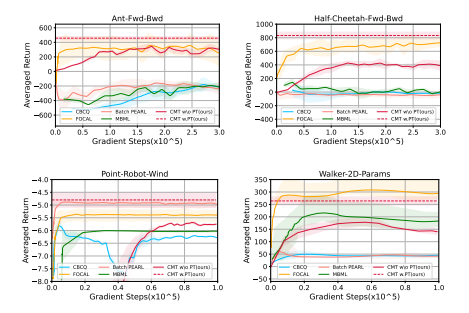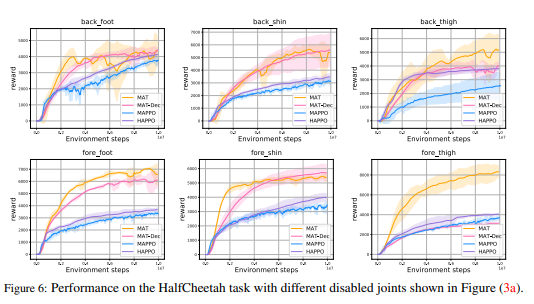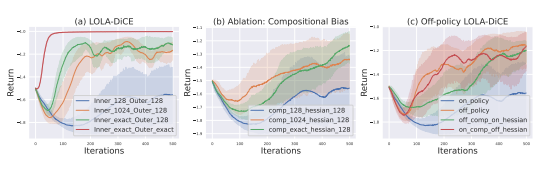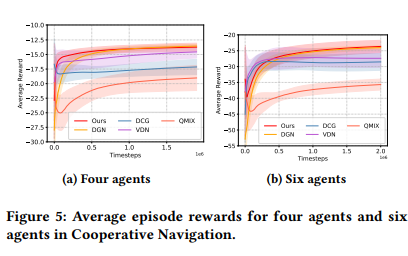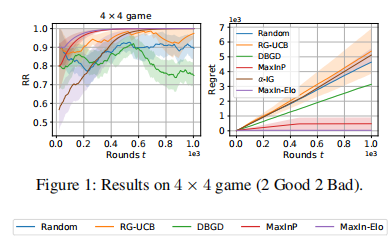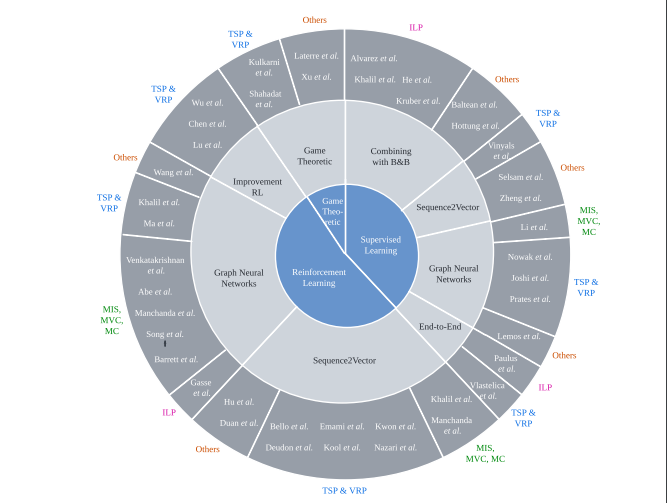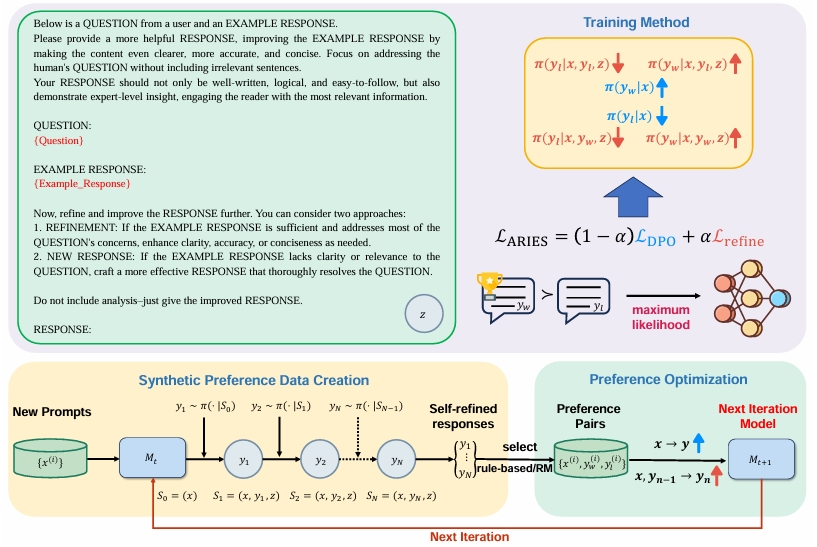
ARIES: Stimulating Self-Refinement of Large Language Models by Iterative Preference Optimization.
Yongcheng Zeng, Xinyu Cui, Xuanfa Jin, Guoqing Liu, Zexu Sun, Quan He, Dong Li, Ning Yang, Jianye Hao, Haifeng Zhang, Jun Wang
arXiv PDF